【韩剧】
1.《未生》
豆瓣评分9.3,是一部改变了职场君职场认知的剧。没有狗血、没有富二代开挂、甚至还没有爱情,非常朴实的一部韩剧。普通的职场新人,发生的职场故事,贴近生活,适合我们普通人。
2.《signal》(信号)
豆瓣评分9.2分,该剧讲述了现在的刑警朴海英和过去的刑警李材韩通过老式对讲机,穿越时空进行连接,并在过程中破获了一些长期未结案件的故事。
3.《我的大叔》
豆瓣9.4分,此剧以拥有相同沉重的生活负担40岁男人与20岁女人出发,讲述他们互相观察并治愈对方的故事。
4.《Live》
豆瓣9.2分,该剧以派出所警察局的故事为中心,讲述为了维持生活中珍贵的价值和正义而努力工作的警察们。
5.《请输入关键词:www》
豆瓣评分8.4分,该剧以门户网站业界的激烈竞争为背景,讲述没有选择成为妻子或母亲的当今女性的真实生活和成功故事。
【日剧】
1.《非自然死亡》
豆瓣评分9.4分,该剧讲述了在“非自然死亡原因研究所”任职的法医三澄美琴与同事们一起探查非正常死亡者的真正死因,从而改变现实世界的故事。
2.《legal high》(胜者即是正义)
两部均分9.3分,该剧讲述的是官司胜诉率高达100%却性格偏执的律师古美门研介,和坦率得有些鲁莽的后辈黛真知子这对“凹凸组合”一起解决疑难案件的故事。
3.《半泽直树》
豆瓣评分9.1分,讲述在泡沫经济时期进入东京中央银行的银行职员半泽直树一边同银行内外的“敌人”斗争,一边贯彻自己的信念“不能像机器一样对待身边的人”,对待恶人要“以牙还牙,加倍奉还”的故事。
4.《花咲舞无法沉默》
豆瓣评分7.0分,曾经是东京第一银行分行的上下级相马健和窗口业务员花咲舞缘分不浅,二人在数月内先后调往银行本部,并分配在临店班供职。所谓临店班,是银行内部指针对出现了问题和纠纷的分店进行现场指导的部门,但是该部门由于其监督职能往往遭到分店负责人的抵制和排斥。
【美剧】
1.《了不起的麦瑟尔夫人》
两部均分8.7,本剧讲述了米琪在经纪人苏西的帮助下继续着她的脱口秀梦想,而离开了米琪的乔尔回到父母所经营的工厂干活,与此同时,他和米琪的心中都还有着对彼此的留恋。这是个关于光鲜和明亮色彩之后的压抑、眼泪的输出,也是关于逆境中的坚强和自如的故事。
2.《爆裂鼓手》
豆瓣评分8.7,一名年轻而有才华的鼓手在一所著名的音乐学院学习,主人公内曼,一心想成为顶级爵士乐鼓手,这个梦想甚至让他有些疯狂。不断地练习打鼓,打,打,打,进入正规乐队开始训练后,在魔鬼导师的鞭策下,这种疯狂更加变本加厉,如果你明确的知道自己想成为一个怎样的人,根本没有借口偷懒。
3.《新闻编辑室》
三部均分9.2!讲述新闻人工作生活的电视剧开播后受到国内剧迷的热捧,在豆瓣评分一度高达9.5。 它将新闻人职场生活的细致展现,也是媒体新手的工作指南。
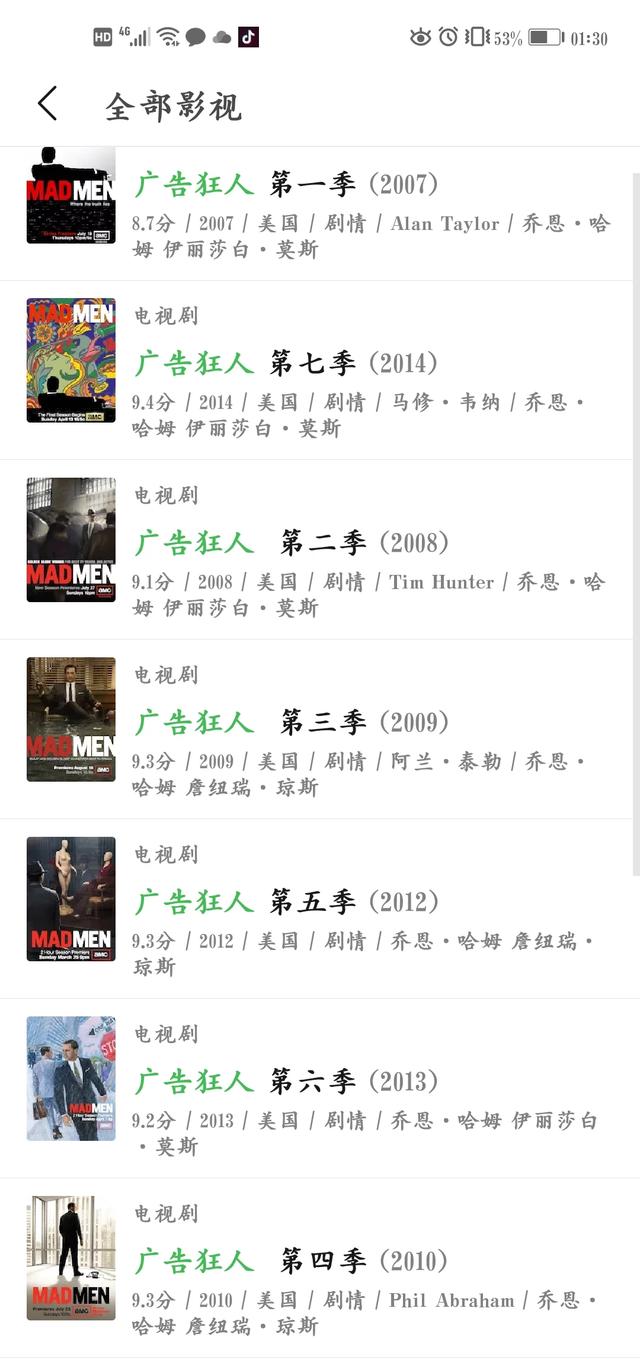
4.《广告狂人》
七部豆瓣均分评分9.2!故事时间设定在上世纪六十年代,但剧中广告狂人们的殚精竭虑和生活挣扎都展现了广告业的残酷竞争,与当下无异。其中的许多广告案例更是堪称经典,连续四年获得艾美奖最佳剧集。
5.《傲骨之战》
两部均分9.4,故事设定在原剧剧终一年后,讲述一个巨大的金融骗局破坏了年轻律师Maia的前途,也令她教母兼导师Diane的储蓄被清,她被逼离开「Lockhart&Lee」,并加入Lucca Quinn的一间芝加哥著名事务所。
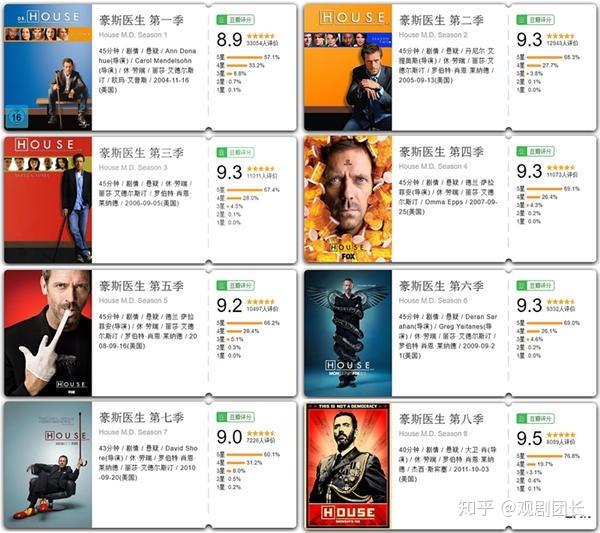
6.《豪斯医生》
8季均分9.3分,在普林斯顿大学附属医院内,坐镇一位大名鼎鼎的内科医师——格雷戈·豪斯,他穿着邋遢随便,手拄拐杖,刚愎自用,锋芒毕露,全然没有人们印象中那类谦和严谨的专业医师的影子。可是在这副令人咋舌的外表之下,却藏着令同行和病患佩服得五体投地的高超医术和丰富学识。豪斯医生治病的手法也独树一帜,他不当面问诊,也绝对不相信病患的道白感受,而完全凭借自己卓越的学识和高超的推理能力解决了诸多疑难杂症。 在神经科医师泰勒·埃瑞克·弗曼、免疫学专家阿丽森·卡梅隆、心脏与急诊科医师罗伯特·蔡斯的协助下,豪斯团队绽放出耀眼夺目的光芒,也创造了一个又一个医学奇迹……
7.《律师本色》
8季9.3分,完全仿真的以法律调查为主题的系列剧,讲述了一帮刑事辩护律师的故事,里面有大量的法庭辩论,以交叉询问为主,精彩的美国法庭戏。
8.《亿万》
3季9.2分,故事主要描述两个华尔街重量级人物之间的战争。精明、强硬的检察官查克·罗兹和才华横溢、极具野心的对冲基金大亨鲍比·阿克塞尔罗德。剧集设定包括了纽约的强权政治和金融活动的权谋诡计,通过错综复杂的叙事特色来编织一个高风险的追捕游戏。
9.《胜利之光》
5季9.1分,讲述了在Texas一支高中橄榄球队Odessa-Permian Panthers在1988赛季比赛的真实故事,故事里的教练、球员及他们的经历都是真实的。
10.《周一清晨》
豆瓣评分9.1分,故事讲述俄勒冈州波特兰市一家医院内五位外科医生,他们在抢救病人的过程中面临无数次艰难选择,错误的选择往往会给他们留下深刻的教训。
11.《猫鼠游戏》
豆瓣评分8.9分,是一个真实的故事。影片所说的“鼠”是一个18岁的男孩弗兰克,擅长伪造文件,通过伪造支票几年间赚了600万美元。后来又假扮飞行员、医生、律师,还收获了一份真爱。影片里的“猫”是FBI探员卡尔,负责侦办弗兰克的诈骗案。卡尔老实、敬业。虽然一次又一次的被弗兰克戏弄,最终还是凭着锲而不舍的努力,抓到了弗兰克。
【国产剧】
1.《杜拉拉升职记1》
豆瓣评分6.1分,主人公杜朝阳是典型的中产阶级代表,她没有背景,受过较好的教育,靠个人奋斗获取成功。杜拉拉在外企的经历跨度八年,从一个朴实的销售助理,成长为一个专业干练的HR经理,见识了各种职场变迁,也历经了各种职场磨练。
2.《我的前半生》
豆瓣评分6.3分,讲述了养尊处优的家庭主妇子君,遭丈夫抛弃后,在金领闺蜜帮助下,一步步重新站起来并再度寻找到幸福的故事。
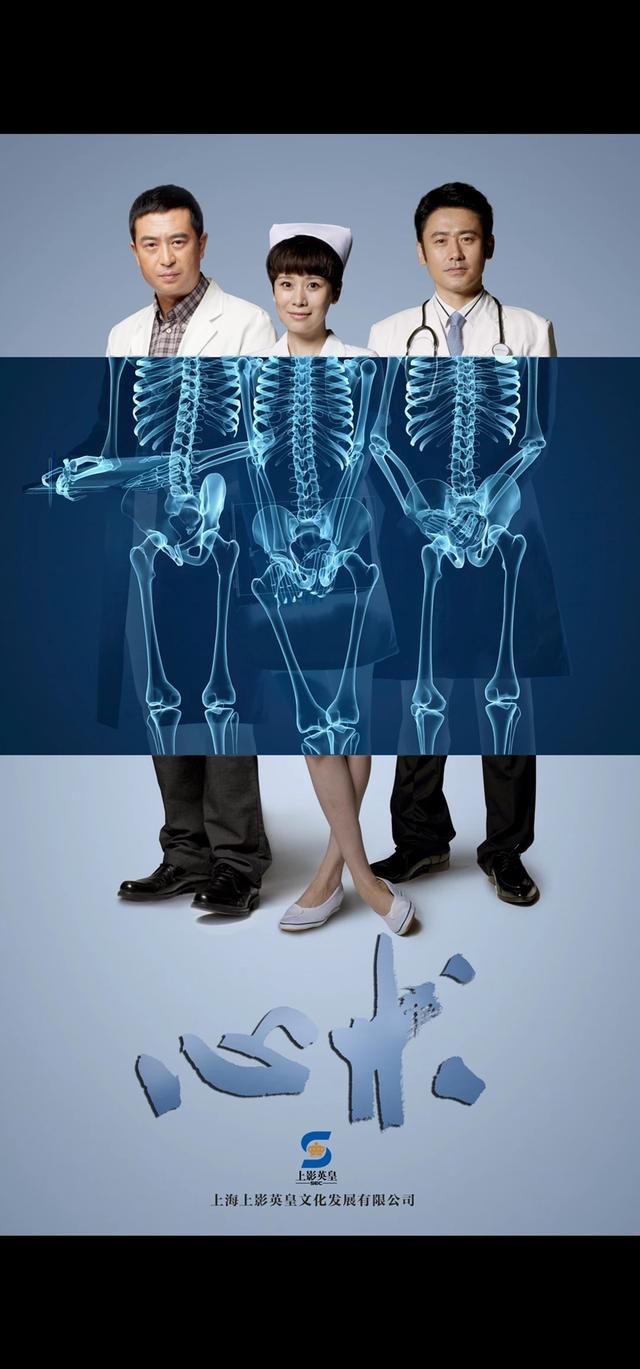
3.《心术》
豆瓣评分8.2分,该剧主要讲述了神经外科医生霍思邈与刘晨曦在医疗战线上精心救治病人并收获美好爱情的故事。
4.《大时代》
豆瓣9.3分,该剧以20世纪60年代至90年代的香港金融市场为背景,透过两个家庭,两代情仇,展现名利与人性的纠缠。
5.《欢乐颂1》
豆瓣评分7.4分,讲述了同住在欢乐颂小区22楼的五个来自不同家庭、性格迥异的女孩们,从陌生到熟悉再到互相体谅、互相帮助、共同成长的故事。
6.《创世纪1:地产风云》
豆瓣评分8.9分,这部片子描写了三个白手起家的好兄弟的创业故事和其中的恩怨情仇。荣添(罗嘉良 饰)、志强(郭晋安 饰)和文彪(陈锦鸿 饰)是三个一起长大的好兄弟。文彪是一名建筑设计师,志强在银行工作,而荣添则出来创业。
7.《都挺好》
豆瓣评分7.8分,讲述了职场金领苏明玉从小不受家人待见,生长在家庭的边缘,在孤独扭曲的环境中长大成人的故事。
8.《金牌投资人》
豆瓣评分7.1分,讲述了当梦想和现实狭路相逢,当事业与爱情两面夹击,方玉斌将如何在激烈的商战竞争中找准自己的位置,遵循自己的内心,成为金牌的投资人的故事。
9.《棋逢对手》
豆瓣评分7.6分,主要讲述了几个年轻人从一家大型超市开始职场历练,逐步进入大卖场最后成为写字楼白领的职场励志故事,通过剧中形形色色的人物的奋斗历程反映了现代都市的职场百态。
有点多,不过都挺不错的,暂时就写到这儿吧~






首推韩剧《未生》
这是一部豆瓣评分9.3的剧
没有狗血、没有富二代开挂、甚至还没有爱情,非常朴实的一部韩剧。普通的职场新人,发生的职场故事,贴近生活,适合我们普通人。
【经典台词】
1. 站在对方的立场,想办法做成这件事情。站在对方的角度重新考虑,必须把事情变得可行。
2. 别急忙下班,再回过头看一下你的位子吧,那样就可以减少失误了。
3. 路不只是用来走的,更重要的是在行走中向前迈进。
4. 挺住,哪个职场人心里没有一份辞呈啊。